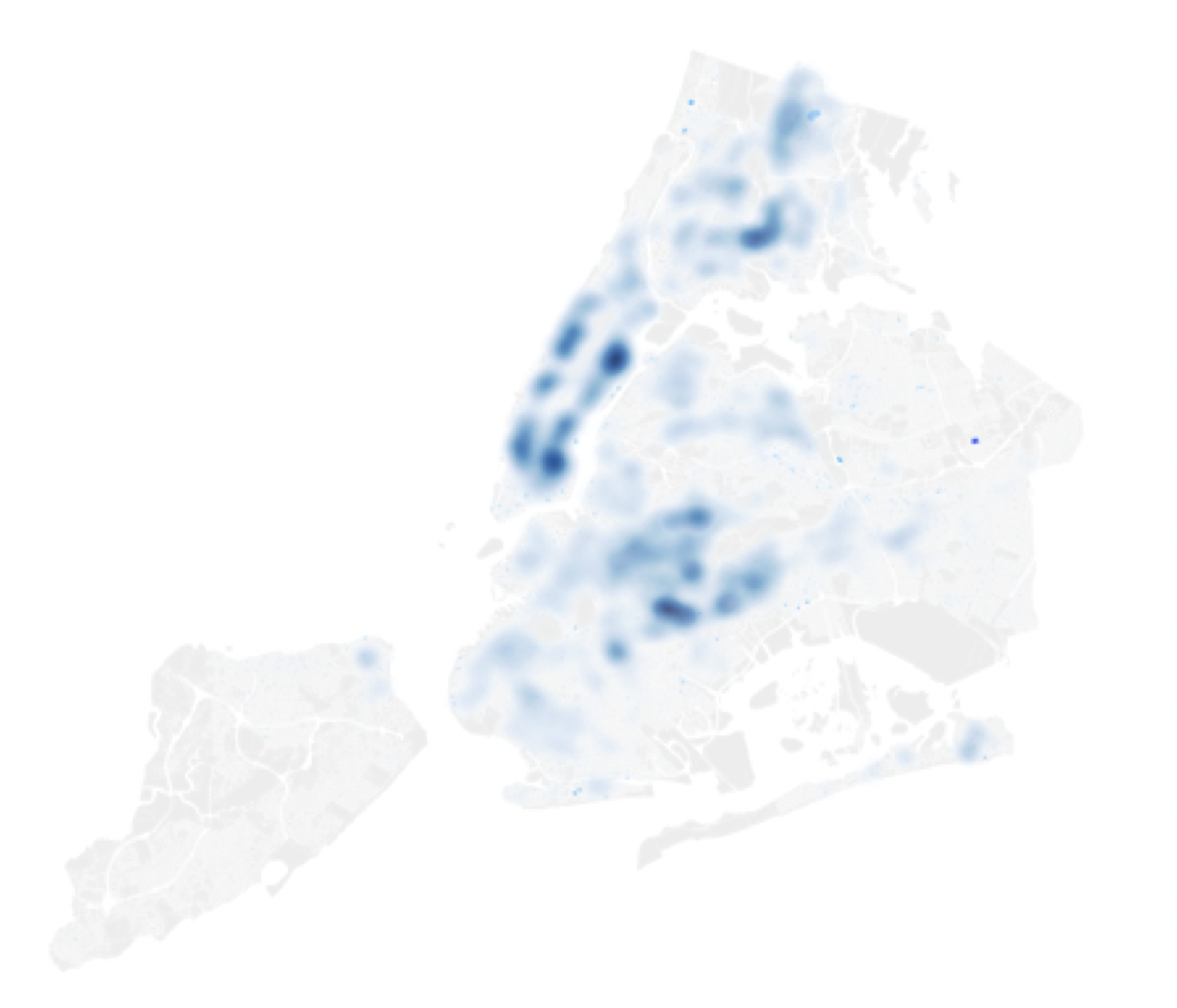
Governance and decision-making in “smart” cities increasingly rely on resident-reported data and data-driven methods to improve the efficiency of city operations and planning. However, the issue of bias in these data and the fairness of outcomes in smart cities has received relatively limited attention. This is a troubling and significant omission, as social equity should be a critical aspect of smart cities and needs to be addressed and accounted for in the use of new technologies and data tools. This paper examines bias in resident-reported data by analyzing socio-spatial disparities in ‘311’ complaint behavior in Kansas City, Missouri. We utilize data from detailed 311 reports and a comprehensive resident satisfaction survey, and spatially join these data with code enforcement violations, neighborhood characteristics, and street condition assessments. We introduce a model to identify disparities in resident-government interactions and classify under- and over-reporting neighborhoods based on complaint behavior. Despite greater objective and subjective need, low-income and minority neighborhoods are less likely to report street condition or “nuisance” issues, while prioritizing more serious problems. Our findings form the basis for acknowledging and accounting for data bias in self-reported data, and contribute to the more equitable delivery of city services through bias-aware data-driven processes.